This is a brief summary of ML course provided by Andrew Ng and Stanford in Coursera.
You can find the lecture video and additional materials in
https://www.coursera.org/learn/machine-learning/home/welcome
Coursera | Online Courses From Top Universities. Join for Free
1000+ courses from schools like Stanford and Yale - no application required. Build career skills in data science, computer science, business, and more.
www.coursera.org
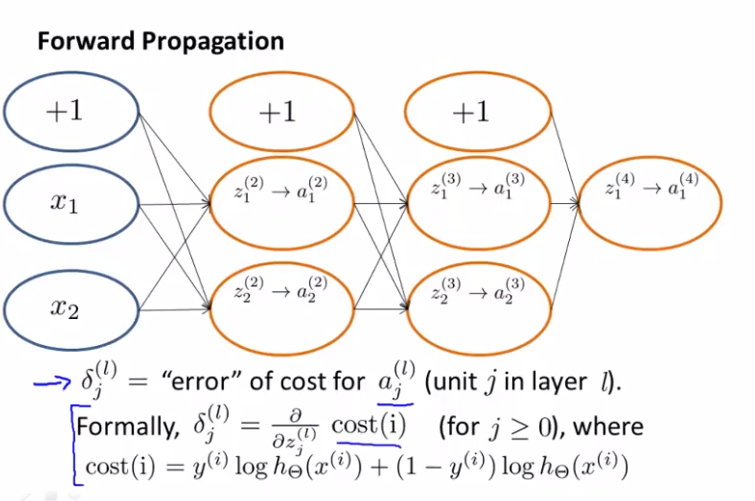
Here is what forward propagation is doing,

- two input units (not counting bias unit on the top)
- two hidden units
- two hidden units
- one output unit
For some particular example, $(x^{(i)}, y^{(i)})$,
1. we feed $x^{(i)}$ into the input layer makes $x_1^{(i)}, x_2^{(i)}$
2. and forward propage to the first hidden layer.
- what we do here is to compute the weighted sum of inputs of the input units $z_2^{(1)}, z_2^{(2)}$
- and we apply the sigmoid of the logistic function (the sigmoid activation function) applied to the z value, $a_1^{(2)}, a_2^{(2)}$.
3. additional forward propage again to get, $z_1^{(3)}, z_2^{(3)}$
- and apply the sigmoid of the logistic function (the sigmoid activation function) to get $a_1^{(3)}, a_2^{(3)}$
4. We get the output value of the neural network $z_1^{(4)}$
- and apply the activation function $a_1^{(4)}$
* note that for magenta circle in the figure below has a value of, weights from each of 3 earlier nodes including the bias times their activation function values. See the figure for the detailed example,

What back propagation is doing is doing a process very similar to above except that instead of the computations flowing from the left to right of this network, the computations instead their flow from the right to the left of the network. And using a very simlar computation as this.
To better understand what backpropagation is doing, let's look at the cost function.

This is a cost function with the only one output unit.
If there is more than one output unit, we will have a summation over the output units indexed by k.
Focusing on a single example $x^{(i)}, y^{(i)}$, the case of 1 output unit, and ignore the regularization

Basically, the cost function here is about how close is the output to the actual observed label y(i).
For backpropagation,
it is computing these $\delta_j^{(l)}$ and we can think of these as the "error of the activation value" that we got for unit j in the layer in the ith layer.
Formally,
delta terms actually are is this, partial derivative of the cost function with respect to z,l,j (weighted sum of inputs)
So, they are a measure of how much would we like to change the neural network's weights, in order to affect intermediate values of the computation so as to affect the final ouput of the neural network h(x) and therefore affect the overall cost.
For the output layer,
set the delta term,
$\delta_1^{(4)} = y^{(i)} - a_1^{(4)} --> this is the difference between actual value of y minus what was the value predicted
next, we are going to propagate these values backwards, and end up computing the delta terms for pervious layers like $\delta_1^{(3)}$, $\delta_2^{(3)}$
And we are going to propagate this further backward, and end up computing $\delta_1^{(2)}$, $\delta_2^{(2)}$

Backpropagation calculation is a lot like running the forward propagation algorithm, but doing it backwards.
it is really a weighted sum of these delta values, weighted by the corresponding edge strength.
So far we have been writing the delta values only for the hidden units, excluding the bias unit.
Depending on how you define the backpropagation algorithm, or how you implement it, you can implement something that computes delta values for those bias units as well. The bias units always output the value of plus one, and they are just what they are and there is no way for us to change the value. we just discard them... Because they don't end up being part of the calculation needed to compute a derivative.
Quiz:


answer: d. probably because $\delta_1^{(3)}$ also deals with other nodes, and with $\delta_1^{(4)}$
Lecturer's Note
Backpropagation Intuition
Recall that the cost function for a neural network is:
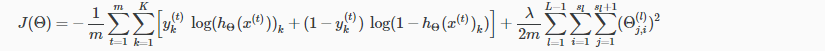
If we consider simple non-multiclass classification (k = 1) and disregard regularization, the cost is computed with:


Recall that our derivative is the slope of a line tangent to the cost function, so the steeper the slope the more incorrect we are. Let us consider the following neural network below and see how we could calculate some $\delta_j^{(l)}$:





